mirror of
https://github.com/Cyan4973/xxHash.git
synced 2026-01-19 04:52:10 +00:00
updated doc
and graphs.
This commit is contained in:
@@ -163,9 +163,9 @@ The new algorithm is much faster than its predecessors,
|
||||
for both long and small inputs,
|
||||
as can be observed in following graphs :
|
||||
|
||||

|
||||
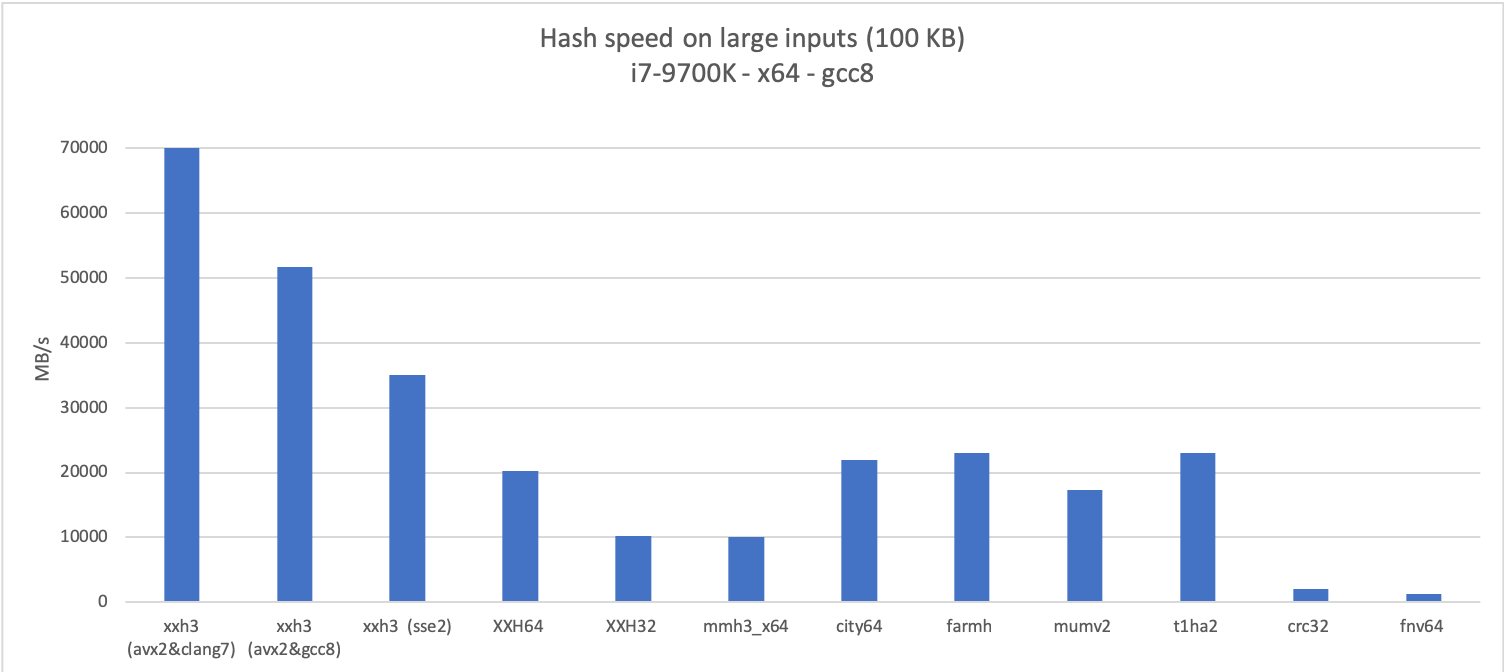
|
||||
|
||||

|
||||

|
||||
|
||||
The algorithm is currently labelled experimental, its return values can still change in a future version.
|
||||
It can be used for ephemeral data, and for tests, but avoid storing long-term hash values yet.
|
||||
|
||||
24
xxhash.h
24
xxhash.h
@@ -317,8 +317,7 @@ struct XXH64_state_s {
|
||||
|
||||
/* ============================================
|
||||
* XXH3 is a new hash algorithm,
|
||||
* featuring vastly improved speed performance
|
||||
* for both small and large inputs.
|
||||
* featuring improved speed performance for both small and large inputs.
|
||||
* See full speed analysis at : http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
|
||||
* In general, expect XXH3 to run about ~2x faster on large inputs,
|
||||
* and >3x faster on small ones, though exact differences depend on platform.
|
||||
@@ -333,10 +332,11 @@ struct XXH64_state_s {
|
||||
*
|
||||
* The XXH3 algorithm is still considered experimental.
|
||||
* Produced results can still change between versions.
|
||||
* It's possible to use it for ephemeral data, but avoid storing long-term values for later re-use.
|
||||
* For example, results produced by v0.7.1 are not comparable with results from v0.7.0 .
|
||||
* It's nonetheless possible to use XXH3 for ephemeral data (local sessions),
|
||||
* but avoid storing values in long-term storage for later re-use.
|
||||
*
|
||||
* The API currently supports one-shot hashing and streaming mode, as well as custom secrets.
|
||||
* The full version will include canonical representation.
|
||||
* The API supports one-shot hashing, streaming mode, and custom secrets.
|
||||
*
|
||||
* There are still a number of opened questions that community can influence during the experimental period.
|
||||
* I'm trying to list a few of them below, though don't consider this list as complete.
|
||||
@@ -345,7 +345,7 @@ struct XXH64_state_s {
|
||||
* That's because 128-bit values do not exist in C standard.
|
||||
* Note that it means that, at byte level, result is not identical depending on endianess.
|
||||
* However, at field level, they are identical on all platforms.
|
||||
* The canonical representation will solve the issue of identical byte-level representation across platforms,
|
||||
* The canonical representation solves the issue of identical byte-level representation across platforms,
|
||||
* which is necessary for serialization.
|
||||
* Would there be a better representation for a 128-bit hash result ?
|
||||
* Are the names of the inner 64-bit fields important ? Should they be changed ?
|
||||
@@ -353,14 +353,14 @@ struct XXH64_state_s {
|
||||
* - Seed type for 128-bits variant : currently, it's a single 64-bit value, like the 64-bit variant.
|
||||
* It could be argued that it's more logical to offer a 128-bit seed input parameter for a 128-bit hash.
|
||||
* But 128-bit seed is more difficult to use, since it requires to pass a structure instead of a scalar value.
|
||||
* Such a variant could either replace current choice, or add a new one.
|
||||
* Such a variant could either replace current one, or become an additional one.
|
||||
* Farmhash, for example, offers both variants (the 128-bits seed variant is called `doubleSeed`).
|
||||
* If both 64-bit and 128-bit seeds are possible, which variant should be called XXH128 ?
|
||||
*
|
||||
* - Result for len==0 : Currently, the result of hashing a zero-length input is `0`.
|
||||
* It seems okay as a return value when using all "default" secret and seed (it used to be a request for XXH32/XXH64).
|
||||
* But is it still fine to return `0` when secret or seed are non-default ?
|
||||
* Are there use cases which would depend on a different hash result for zero-length input when the secret is different ?
|
||||
* Are there use cases which could depend on generating a different hash result for zero-length input when the secret is different ?
|
||||
*/
|
||||
|
||||
#ifdef XXH_NAMESPACE
|
||||
@@ -381,7 +381,7 @@ struct XXH64_state_s {
|
||||
|
||||
/* XXH3_64bits() :
|
||||
* default 64-bit variant, using default secret and default seed of 0.
|
||||
* it's also the fastest one. */
|
||||
* It's the fastest variant. */
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void* data, size_t len);
|
||||
|
||||
/* XXH3_64bits_withSecret() :
|
||||
@@ -389,9 +389,9 @@ XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void* data, size_t len);
|
||||
* This makes it more difficult for an external actor to prepare an intentional collision.
|
||||
* The secret *must* be large enough (>= XXH3_SECRET_SIZE_MIN).
|
||||
* It should consist of random bytes.
|
||||
* Avoid repeating same character, and especially avoid swathes of \0.
|
||||
* Avoid repeating sequences of bytes within the secret.
|
||||
* Failure to respect these conditions will result in a bad quality hash.
|
||||
* Avoid repeating same character, or sequences of bytes,
|
||||
* and especially avoid swathes of \0.
|
||||
* Failure to respect these conditions will result in a poor quality hash.
|
||||
*/
|
||||
#define XXH3_SECRET_SIZE_MIN 136
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void* data, size_t len, const void* secret, size_t secretSize);
|
||||
|
||||
Reference in New Issue
Block a user